首先,先说明一个问题。这样的结果出现,说明系统设计是有问题的。
其次
删除重复数据,你要提供你是什么衫友薯数据库。
不同数据库会有不同的解决方案。
关键字Distinct 去除重复,如下列SQL,去除Test相同的记录;
1. select distinct Test from Table
2. 如果是要删除表中存在的重复记录,那就逻辑处理,如下:
3. select Test from Table group by Test having count(test)>1
4. 先查询存在重复的或者数据,后面根据条件删除
还有一个更简单的方法可以尝试一下:
select aid, count(distinct uid) from 表名 group by aid
这是sqlserver 的写法。
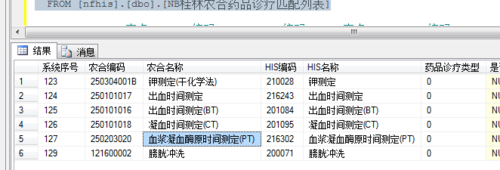
如图一在数据表中有两个膀胱冲洗重复的记录。
2
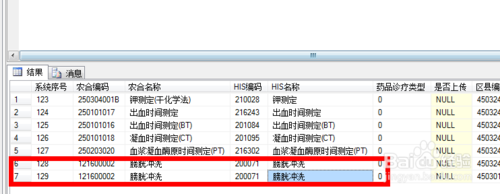
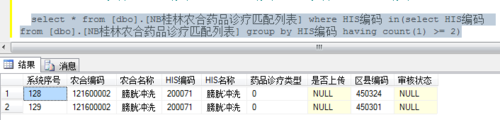
可以告信通过sql语句“select *from 表名 where 编码 in(select 编码 from 表名 group by 编码 having count(1) >= 2)”来查询出变种所有重复的记录如图二
3
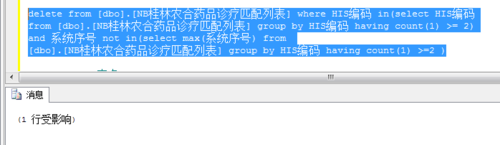
通过sql语句"
delete from 表名 where
编码 in(select 编码 from 表名 group by 编码 having count(1) >= 2)
and 编码 not in (select max(编码)from 表名 group by 编码 having count(1) >=2)
"来删除重复的记录只保留编码最大的记录